




Retrouvez toutes nos autres videos sur notre chaîne YouTube.
Dans cet article, nous allons discuter des étapes clés pour concevoir un système de recherche sémantique. Nous allons énumérer les différences entre un moteur de recherche classique et un moteur de recherche sémantique. Nous aborderons les étapes de prétraitement, la génération d’un vecteur mathématique à l’aide d’un modèle de langage, les méthodes d’entraînement, ainsi que le choix de la meilleure base de données pour le stockage.
Voici un cas concret, prenons l’exemple d’une base documentaire d’articles scientifiques sur diverses thématiques médicales (médicaments, traitements, matériel…). Comment identifier rapidement les articles les plus pertinents en fonction d’une recherche spécifiques ?
Voici la méthode que nous proposons.
1/ Moteur de recherche Sémantique et moteur de recherche classique : quelle différence ?
Un moteur de recherche classique utilise principalement des algorithmes de recherche basés sur des mots-clés pour trouver des correspondances entre les termes recherchés et les pages web indexées. Cela signifie que si vous effectuez une recherche en tapant des mots-clés, le moteur de recherche classique renverra des résultats basés sur ces mots-clés.
En revanche, un moteur de recherche sémantique utilise une compréhension plus avancée de la signification des mots pour effectuer des recherches. Il s’appuie sur l’analyse du sens des mots plutôt que sur leur simple correspondance. Il est capable de comprendre la signification des requêtes complexes et d’afficher des résultats plus précis en fonction du contexte de la recherche.
Par exemple, si vous effectuez une recherche avec un moteur de recherche sémantique pour « recettes de cuisine italienne », il va chercher des pages qui contiennent des informations sur la cuisine italienne et non simplement des pages qui contiennent les mots « recettes » et « italienne ». En outre, un moteur de recherche sémantique sera capable de comprendre les synonymes et les termes liés à la requête, ce qui améliore la pertinence des résultats.
En somme, la principale différence entre les deux types de moteurs de recherche réside dans leur capacité à comprendre le sens et le contexte de la requête de recherche pour afficher des résultats plus précis et pertinents.
2/ Les étapes de création d’un moteur de recherche sémantique
Pour mettre en place un moteur de recherche sémantique, plusieurs étapes sont nécessaires
2.1 / Nettoyage et preprocessing des textes des documents :
Le nettoyage fait référence aux étapes que vous effectuez pour normaliser votre texte et supprimer les caractères et les mots qui ne sont pas pertinents. Cette étape est essentielle pour éliminer le bruit dans le texte. Le bruit comprend tous les caractères ou mots qui ne sont pas utiles pour les algorithmes que nous allons utiliser pour les modèles de machine Learning. On peut par exemple supprimer les stops words, les caractères spéciaux, les ponctuations, veiller aux espaces en trop, éviter les “lemmatisation” et les racinisation” dans le cas d’utilisation de modèles de deep learning, etc [1].
2.2/ Tokenization :
La tokenisation le processus de conversion d’un texte brut en une séquence de « tokens », qui peuvent être traités par des algorithmes de traitement du langage naturel. Ces tokens peuvent être des mots individuels, des sous-mots, des phrases ou même des paragraphes entiers, selon les besoins de l’application.
- Tokenization des mots : “Apple is looking at buying U.K. startup for $1 billion” devient [“Apple”,”is”,” looking”,”at”,”buying”,”U.K.”,”startup”,”for”,”$”,”1”,”billion”]
- Tokenization par phrase : Smith, recently had a Ph.D. in neurology . His groundbreaking work led to the discovery of a new treatment for the disease . [“Dr. Smith, recently had a Ph.D. in neurology” ,“His groundbreaking work led to the discovery of a new treatment for the disease”]
La vigilance est de rigueur. Par exemple, dans le cas où on souhaite faire un découpage par phrase, cette étape peut sembler facile, car a priori, il suffit de couper chaque phrase lorsqu’un point est rencontré. Mais en réalité, il faut prendre en compte des cas spéciaux, par exemple la présence d’un point au milieu d’un chiffre, comme « 200.000 ». Pour cela, il est préférable d’utiliser des méthodes prédéfinies, comme dans Spacy où l’on peut utiliser « doc.sents » pour extraire les phrases en prenant en compte le contexte.
2.3 / Génération d’embeddings
Pour pouvoir apprendre des modèles qui vont retrouver des informations similaires, il est nécessaire de transformer les textes en vecteurs numériques, avec un algorithme qui va représenter les informations dans un espace vectoriel et calculer la proximité entre ces vecteurs. C’est ce qu’on appelle la génération des embeddings (ou vecteurs).
Contrairement aux vecteurs “sparse” générés par les méthodes classiques telles que les sacs de mots, TF-IDF… les embeddings permettent une représentation dense et continue des données textuelles, qui peut capturer des informations sémantiques plus fines.
Il existe plusieurs façons de vectoriser un texte, avec différents modèles. On peut créer ainsi un vecteur par mot (Word2Vec), ou un vecteur par phrase (Sentence Transformers), ou par sous-mot (FastText), ou même par document (Doc2Vec). Les embeddings permettent une représentation dense et continue des données textuelles, qui peut capturer des informations sémantiques plus fines que les vecteurs « sparse ».
2.4/ Calcul de la similarité
Prenons par exemple la vectorisation des phrases pour notre système de recherche sémantique.
L’objectif sera donc de déterminer si deux phrases (la requête et une phrase de document), sont sémantiquement similaires. Pour y parvenir, une méthode simple consiste à représenter chaque phrase par un vecteur numérique, de sorte que la comparaison de deux phrases revient simplement à comparer leurs vecteurs correspondants en utilisant un calcul de distance entre les vecteurs, tel que la distance cosine, la distance euclidienne ou la distance de Manhattan.
Nous avons choisi la distance cosine pour notre exemple, qui calcule l’angle entre ces vecteurs dans l’espace vectoriel. Plus l’angle est petit, plus les deux vecteurs sont similaires.
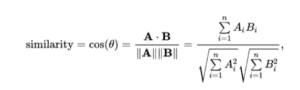
Les scores étant compris dans un intervalle de -1 à 1, ils sont donc normalisés avec la formule suivante Pour obtenir un score compris entre 0 et 1:
normalized_similarity = (similarity + 1) / 2
2.5 /Stockage de ces embeddings dans une base
Il est primordial de stocker les embeddings de chaque phrase, afin de ne pas avoir à recalculer les embeddings de toutes les phrases de notre base de données à chaque fois.
Les vecteurs d’embeddings ont une dimension considérable et stocker ces vecteurs de grande taille dans une base de données relationnelle peut poser des problèmes de performances et de scalabilité. Afin de stocker efficacement des vecteurs de grande taille, il est courant d’utiliser des solutions de stockage spécialisées telles que des bases NoSQL ou des bases de données big data avec des fichiers distribués. Ces bases sont conçues pour stocker et gérer des données non structurées de manière efficace et scalable. Plusieurs solutions sont disponibles :
- Elastic Search : Elasticsearch est un moteur de recherche distribué open-source qui peut être utilisé pour stocker et rechercher des embeddings, et il est connu pour sa rapidité de recherche et est souvent utilisé dans les applications nécessitant une recherche en temps réel .
- Milvus : Milvus est une base de données open source de recherche vectorielle conçue pour stocker et rechercher efficacement des vecteurs de haute dimension tels que des embeddings. Elle est conçue pour répondre aux besoins des applications de recherche similaire et de classification de contenu, telles que la recherche d’images, de vidéos, de produits et de documents.
- OpenSearch : OpenSearch est une version d’Elasticsearch entièrement open source et communautaire, elle offre plus d’option de sécurité et de conformité que elastic seach ,par exemple un meilleur système d’authentification et d’autorisation d’accès , ainsi que la possibilité de chiffrer les données .
- MongoDB : MongoDB est une base de données NoSQL qui stocke des données sous forme de documents JSON. Elle est connue pour sa scalabilité et sa flexibilité, ce qui en fait un bon choix pour le stockage d’embeddings.
- Faiss : Faiss est une bibliothèque open source de recherche de similarité et de regroupement de vecteurs denses. Elle est spécifiquement conçue pour travailler avec des embeddings à grande dimension et peut être utilisée en combinaison avec d’autres bases de données SQL pour effectuer des opérations de recherche de similarité efficaces.
Chacune de ces bases de données est adaptée à des cas d’utilisation différents et possède ses propres avantages et inconvénients. Le choix de la base de données dépendra des besoins de l’application, de la quantité de données à stocker, de la complexité des opérations de recherche et des ressources disponibles.
Il est essentiel de stocker les métadonnées, en plus du contenu textuel, afin de faciliter la recherche et le regroupement de phrases similaires. Les métadonnées comprennent des informations telles que le numéro de page, le numéro de phrase dans la page, le nom du document, le numéro de section et d’autres flags. Ces métadonnées sont importantes dans l’étape de tri et de classement des documents les plus pertinents pour une requête de recherche. Elles permettent de donner plus de poids ou d’importance à certaines phrases par rapport à d’autres. Les métadonnées sont donc un élément clé pour améliorer l’efficacité et la pertinence des résultats de recherche dans les bases de données de documents.
3/ Un exemple d’entraînement d’embedding de phrase : le modèle Sentence Transformer
Il existe une architecture qui se base sur les modèles BERT et qui ont été ajustés spécifiquement pour la création d’embeddings de phrases. Ils sont appelés des « sentence transformers » et l’un des moyens les plus simples d’utiliser l’un de ces modèles est via la bibliothèque (sentence-Transformers)
Il est possible d’entraîner son propre modèle, ou bien d’utiliser des modèles pré-entraînés disponibles sur le site de Sentence Transformer. [2]
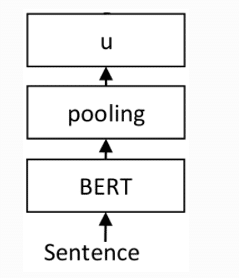
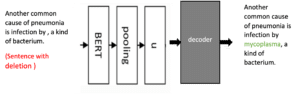
L’architecture suivante composée d’une couche BERT et d’une couche de regroupement (pooling), est un modèle Sentence Transformer.
Le vecteur finale u, représente donc le vecteur d’embedding de notre phrase.
Avant de commencer l’entrainement du Sentence Transformer, on doit choisir quel modèle Bert utiliser, étant donné que sentence transformer s’appuie sur un modèle Bert pré-entrainé.
Les modèles Bert (langage model) sont entraînés sur une grande quantité de données afin de capturer l’essentiel de la langue. Le choix du modèle Bert dépendra de la langue utilisée dans notre cas d’utilisation (français, anglais, multilingue) ainsi que de la vitesse de l’application finale et des ressources disponibles. Plusieurs modèles Bert pré-entraînés [3] sont disponibles sur le site de Hugging Face.
Par exemple, le modèle bert-base-uncased est pré-entraîné sur 3,3 milliards de mots provenant de toutes les pages Wikipédia en anglais et de livres en anglais.
3.1/ Entrainement supervisé du Sentence Transformer [4]
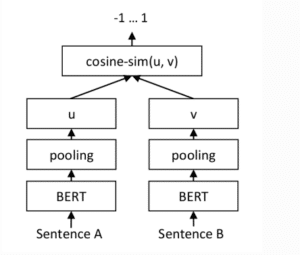
La manière la plus simple est d’avoir des paires de phrases annotées avec un score indiquant leur similarité, par exemple sur une échelle de 0 à 1. Nous pouvons ensuite entraîner le réseau avec une architecture de réseau Siamese (Sentence Embeddings using Siamese BERT-Networks).
Pour bien comprendre l’étape d’entrainement en utilisant l’architecture Siamese, nous l’expliquons plus en détail dans le paragraphe suivant.
Un réseau de neurones Siamese est composé de deux sous-réseaux identiques qui produisent deux embeddings u et v pour deux phrases données. Ces deux vecteurs sont ensuite comparés pour calculer la distance de similarité entre les deux phrases. Pendant l’entraînement, les poids du réseau sont ajustés pour minimiser une fonction de perte (CosineSimilarityLoss) qui mesure la différence entre les distances de similarité prédites par le réseau et les vraies valeurs.
Le réseau est ensuite entraîné sur l’ensemble d’entraînement jusqu’à ce que les distances de similarité prédites soient suffisamment proches des vraies valeurs. Les deux sous-réseaux restent identiques grâce à une technique appelée « Weight sharing », qui se base sur le calcul de gradient combiné.
Il est bon de savoir que d’autres méthodes sont également disponibles, par exemple en utilisant un ensemble de données d’entraînement contenant un triplet (ancre, similaire 1, similaire 2) où la première position est la phrase d’ancrage, suivie d’une autre phrase similaire, et en troisième position une phrase non similaire. La fonction de perte utilisée dans ce cas est appelée Triplet Loss.
3.2/ Entrainement non supervisé
Il existe plusieurs méthodes pour entraîner un modèle Sentence Transformer sans avoir besoin de données d’entraînement labellisées. Ces méthodes permettent d’apprendre les embeddings sémantiques à partir du texte ou des phrases elles-mêmes.
Dans notre cas, nous allons utiliser une méthode appelée TSDAE (Transform-based Denoising Autoencoder). Le TSDAE [5] est une architecture d’encodeur-décodeur utilisée pour entraîner notre modèle Sentence Transformer, afin qu’il puisse générer des vecteurs numériques qui capturent la signification sémantique d’une phrase.
Pendant la phase d’entraînement, l’encodeur prend une phrase endommagée en entrée et la transforme en un vecteur de taille fixe. Le décodeur est alors chargé de reconstruire la phrase d’origine à partir de ce vecteur. Le bruit peut être ajouté de différentes manières, telles que la suppression de mots, la perturbation de la syntaxe ou la permutation de mots. L’ajout de ce bruit permet au TSDAE de s’entraîner sur des phrases plus diversifiées et de renforcer sa capacité à capturer la sémantique sous-jacente.
D’autres méthodes sont également disponibles, telles que :
- MLM (Masked Language Modeling)
- SimCSE (Simple Contrastive Learning of Sentence Embeddings)
- CT (In-Batch Negative Sampling)
4/ Architecture globale de notre système
Plusieurs bibliothèques sont disponibles pour mettre en place tous ces composants plus facilement. On peut citer un framework appelé Haystack [6] et ses différentes classes disponibles, telles que le document store pour le stockage dans une base de données, l’embedding retriever pour la génération ou la récupération des embeddings de la base, etc.
L’application finale peut être rendue accessible via une API, qui peut être mise en place à l’aide de plusieurs bibliothèques telles que Flask ou FastAPI.
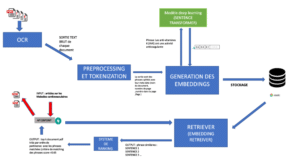
Notre système global est représenté dans la figure suivante :
Conclusion
Dans cet article, nous avons présenté les différentes étapes de la construction d’un moteur de recherche sémantique, en mettant l’accent sur les prétraitements et le nettoyage des données, la génération des embeddings à l’aide du modèle Sentence Transformer, ainsi que les méthodes d’entraînement disponibles. Nous avons également souligné l’importance du choix de la base de données pour stocker ces embeddings.
La construction d’un moteur de recherche sémantique peut sembler complexe, mais en suivant les bonnes pratiques (qualité du prétraitement, choix d’embeddings adaptés au domaine d’étude, etc.), vous pouvez créer un système de recherche précis et pertinent pour vos utilisateurs.


