




Comment l’Intelligence Artificielle révolutionne la détection de fraudes.
L’accroissement du volume des données dans le secteur de l’assurance, de la banque et dans les télécommunications permet aujourd’hui d’appliquer des solutions data science afin de mieux détecter les fraudes.
Selon l’étude de « l’International Data Corporation », le secteur bancaire investira plus que tout autre secteur sur les technologies data en 2019.
L’objectif de ces investissements vise non seulement à diminuer les fraudes externes, internes ainsi que les fraudes managériales, mais aussi à stopper le plus rapidement possible ces attaques et donc permettre une limitation des pertes. Le ROI significatif favorise la mise-en-place de ces projets.
Afin de réaliser ces détections, les banques misent aujourd’hui sur l’application de techniques d’intelligences artificielles. Ces algorithmes, qu’ils soient supervisés ou non, permettent d’identifier des comportements atypiques et suspects.
Les enjeux majeurs dans l’amélioration de la sécurité sont :
- L’automatisation de l’analyse des données afin d’augmenter la vitesse du traitement traditionnel et donc d’améliorer la vitesse de détection
- L’identification des patterns des transactions indésirables
- L’apprentissage continu et temps réel de la détection des anomalies
La puissance de ces analyses vient de leurs capacités à effectuer le traitement de toutes les transactions en temps réel et à découvrir de manière automatique les anomalies. Ce qui permet non seulement de créer de nouveaux outils de détection de fraudes mais aussi d’accompagner les outils existants en les challengeant et les renforçant grâce à de nouvelles informations.
Alors quelles sont les limites de ces algorithmes « miraculeux » ? Ils sont de fait confrontés à 2 problématiques interconnectés :
- Une détection suffisamment stricte : Les algorithmes de détection de fraudes se doivent d’être suffisamment performant en signalant tous comportements suspects afin de ne pas laisser passer de fraude. Ainsi les comportements frauduleux classifiés comme faux négatifs nécessitent de détecter les types de fraudes non préconisées par le système.
- Une détection suffisamment pertinente : Les algorithmes de détection de fraudes se doivent de limiter au plus les faux positifs, qui sont notamment dus à des comportements non frauduleux mais inhabituels (vacances, soldes, etc.).
Ces deux problématiques peuvent être résolues par différents traitements sur les algorithmes mais, bien souvent, influer sur l’une a des conséquences sur l’autre.
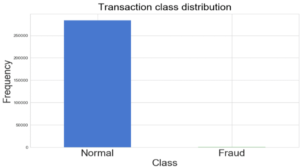
La dissymétrie des informations dans les cas de détection de fraudes (i.e. le faible ratio d’actions frauduleuses sur l’ensemble de BDD) est la principale difficulté. C’est pourquoi les Data Scientists essaient d’optimiser leurs méthodologies pour mieux étudier les données déséquilibrées de façon à diminuer les faux négatifs et positifs.
La détection de fraude par des outils d’analyse prédictive et de détection des anomalies comporte deux phases :
- L’analyse d’implication et l’analyse criminalistique des données historiques pour construire le modèle d’apprentissage automatique.
- L’utilisation du modèle en production pour établir des prédictions sur les événements.
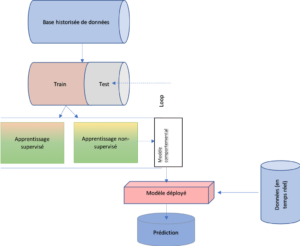
Le choix des algorithmes dépend de la temporalité et du nombre de cas de fraudes dans l’ensemble d’une base de données :
- Si les cas de fraudes ne représentent qu’une faible proportion de la totalité des observations, les algorithmes d’apprentissage non-supervisé sont souvent les plus appropriés.
Dans cette approche, la détection d’une anomalie comme une fraude nécessite de classifier des actions « normales » en se basant sur des caractéristiques communes. Les actions « anormales » correspondent au nombre et au pourcentage des comportements non classifiés comme normaux. Dans cette solution non-supervisée, les outliers déclarés comme des cas anormaux se trouvent loin de leurs pairs.
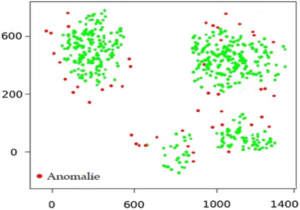
L’avantage de cette méthode est sa vitesse, sa limite majeure est le risque de faux négatifs car des cas de fraudes peuvent être classifiés dans un même cluster que des comportements inhabituels. De plus, l’algorithme peut produire des alertes dites « faux positifs » pour des individus semblant avoir un comportement marginal.
- Les algorithmes d’apprentissages supervisés nécessitent quant à eux un dataset d’apprentissage labélisé. La performance du modèle de détection de fraude dépend de la sélection et de la manipulation des variables les plus pertinentes. Le feature engineering, pour l’identification des meilleures variables explicatives des comportements frauduleux nécessite d’analyser par exemple, la dimension du temps, la localisation géographique et la fréquence des actions. L’idée d’utiliser des méthodes supervisées de Machine Learning est de permettre de minimiser le biais d’estimation dans la prédiction de la valeur ou la probabilité d’être une fraude.
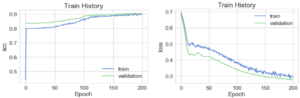
Leur objectif est de distinguer le comportement normal de comportement frauduleux. L’une des limites de ces méthodes d’apprentissage supervisé est liée aux algorithmes qui ne contrôlent pas le jeu de données à la fois à court terme et long terme.
- Comme solution à ce problème de temporalité, Il existe des méthodes semi-supervisées contrôlant le jeu de données à court et à long terme par des architectures spécifiques de réseaux de neurones.
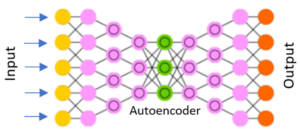
Le nombre de sorties est égal au nombre d’entrées du réseau. Le but du modèle de réseau de neurones est de réduire la dimension (encode) en éliminant des neurones utilisés au niveau de la couche intermédiaire entre l’entrée et la sortie du réseau. Autoencoder permet de diminuer les erreurs pour la reconstruction du signal sur la deuxième moitié du réseau de neurones. Ainsi, les comportements anormaux peuvent être classifiés grâce aux grands résidus ayant des valeurs plus importantes que les comportements normaux.
Le déséquilibre d’un jeu de données, i.e. le fait d’avoir beaucoup plus de cas non frauduleux que frauduleux, conduit souvent à un mauvais apprentissage par les modèles supervisés. Il existe trois approches principales de traitement des données déséquilibrés afin de rendre les modèles plus performants.
I. Pré-Traitement du dataset (2 méthodes)
- La première méthode, dite du sur-échantillonnage(oversampling), implique de réduire ou d’éliminer le déséquilibre dans l’ensemble de données en répliquant ou en créant de nouvelles observations de la classe minoritaire. Il existe trois types de techniques :
- Sur-échantillonnage aléatoire : Il permet de créer des nouvelles instances de la classe de minorité en répliquant de manière aléatoire des échantillons existants afin d’augmenter le nombre de minorités dans l’ensemble de données. Le problème de l’overfitting est la limite de l’utilisation de cette méthode car ellereproduit simplement les instances déjà existantes de la classe minoritaire.
- Sur-échantillonnage basé sur un clustering :On applique un k-moyennes séparément aux instances majoritaires et minoritaires. Une fois que l’on a identifié les clusters dans le jeu de données, chaque groupe est sur-échantillonné de sorte que tous les groupes aient le même nombre d’observations. Là encore, il existe un risque de sur-apprentissage dans ce modèle.
- Sur-échantillonnage dit synthétique :Il permet d’éviter les sur-ajustements. Dans cette méthode, des exemples synthétiques du sous-ensemble de minorité sont créées pour équilibrer l’ensemble de données. Ces nouvelles données peuvent être générées avec différentes méthodes : SMOTE,ADASYN, Bayesian inference, GAN…. Cela ajoute de nouvelles informations à l’ensemble de données et augmente le volume total du jeu de données. Si on laisse de la place au bruit et aux distributions inhérentes à la classe minoritaire, cette méthode s’appelle sur-échantillonnage dit « synthétique modifié ».
- La deuxième méthode, dite du sous-échantillonnage,implique de réduire ou d’éliminer le déséquilibre dans l’ensemble de données en se concentrant sur la classe majoritaire. Les méthodes de clustering et aléatoire peuvent être appliquées sur la classe majoritaire de façon à les éliminer de manière aléatoire. Ces techniques peuvent éliminer des informations ou les points de données pouvant être utiles pour la classification, c’est pourquoi elles sont peu utilisées.
II. Modification des métriques
Une autre solution pour améliorer les performances des algorithmes sur des jeux de données déséquilibrés est de travailler sur la métrique de validation. Pour la détection de fraude, plutôt que d’utiliser l’accuracy, nous utiliserons les métriques suivantes :
- Le Rappel: Il s’agit d’un indicateur du nombre d’éléments correctement identifiés comme positifs (frauduleux) par rapport au total des positifs réels. Cette méthode permet de minimiser les faux négatifs, donc de détecter au maximum les vrais cas de fraudes.
- Précision: Il s’agit d’un indicateur du nombre d’éléments correctement identifiés comme positifs (frauduleux) sur le total des éléments identifiés. Cette méthode permet de minimiser les faux positifs, donc de minimiser le désagrément utilisateur.
- F1: C’est un score de performance qui combine précision et rappel. C’est une moyenne harmonique de la précision. Elle permet de combiner les deux approches précédentes. La formule est la suivante :
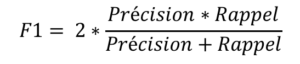
- Score du coefficient de corrélation de Matthew: Il s’agit d’un score de performance qui prend en compte les vrais et faux positifs, ainsi que les vrais et faux négatifs. Ce score donne une bonne évaluation du jeu de données déséquilibré.
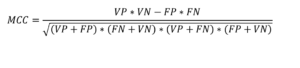
III. Algorithmes spécifiques
Enfin, certains algorithmes permettent de limiter l’impact du déséquilibre :
- Le Gradient Boosting Machine (GBM) et les arbres de décision fonctionnent souvent bien sur des jeux de données déséquilibrés, car leur structure hiérarchique leur permet d’apprendre les signaux des deux classes.
- Une autre tactique consiste à utiliser des algorithmes d’apprentissage pénalisés qui augmentent le coût des erreurs de classification pour la classe minoritaire. Un algorithme populaire pour cette technique est le « Penalized-SVM », mais d’autres algorithmes tels que le Weighted random forest peuvent être utilisés.
Conclusion
L’augmentation des volumes de données et de la performance des algorithmes mettent en évidence la nécessité d’intégration de ces nouvelles techniques dans les systèmes traditionnels de traitement de l’analyse des actes frauduleux.
L’avantage d’implémenter un système adaptatif et sensible est d’identifier les risques de fraude de manière plus fine, précise et réactive.
L’utilisation des modèles non supervisés permet d’atteindre cet objectif de réactivité en permettant d’identifier tous les comportements qui s’éloignent de la normale.
Quant aux modèles supervisés, une fois que sont corrigés les biais dû à la dissymétrie des données ainsi que ceux dû à la temporalité et l’hétérogénéité des comportements, leurs performances surpassent souvent nettement celles des modèles classiques. Malheureusement leur limite est souvent leur non explicabilité qui les rend inutilisables pour des aspects réglementaires.
C’est pourquoi dans le paradigme de la détection de fraude, l’approche métier classique et l’approche IA sont souvent complémentaires. L’une apportant du sens à l’autre, quand l’apport de ces nouveaux algorithmes permet non seulement de challenger les modèles dit classiques mais aussi de fournir de nouvelles features et indicateurs pour l’amélioration continue de ces modèles.


