




Dans ce nouvel article, nous nous intéressons aux capacités des réseaux de neurones pour la résolution de problèmes d’Intelligence Artificielle (IA) sous l’angle historique des fondements théoriques des réseaux de neurones, aujourd’hui largement présents dans l’industrie.
1. Le contexte de l’intelligence artificielle
Après plusieurs décennies de recherche, l’intelligence artificielle est entrée brutalement dans de nombreuses applications industrielles : lecture automatique de caractères manuscrits, reconnaissance de visages… En moins de 10 ans, ces applications techniques relevant de l’Intelligence Artificielle sont vastes, et restent pour le grand public, comme pour les professionnels non spécialistes, un domaine rempli d’images d’Épinal.
S’il est clair que l’Intelligence Artificielle est intimement liée au concept de « cognition », ce qui n’est pas clairement démystifié, aujourd’hui, est la nature des fonctions cognitives humaines et animales pouvant être assurée par cette discipline. En effet, ces capacités recouvrent une grande diversité de tâches allant des processus de traitement de l’information de haut niveau comme la mémoire, la prise de décision, le raisonnement, aux processus plus élémentaires et/ou de plus bas niveau comme la perception, la motricité et même l’émotion — l’émotion étant un facteur déterminant lors de la prise de décision.
L’évolution technologique observée depuis le début des années 2010 dans le domaine des composants électroniques (processeurs, cartes graphiques, composants numériques programmables) a permis de mettre en lumière la capacité de l’IA à traiter ces problématiques complexes dans un contexte industriel. Nombre d’applications professionnelles et grand-publics partagent maintenant ces avancées impressionnantes, mais restent essentiellement cantonnées au champ de la perception visuelle et sonore, comme la reconnaissance de forme et de la parole .
Même si ces résultats sont impressionnants, l’état de la recherche mathématique et de la technologie ne permettront pas à court terme de reproduire des capacités cognitives plus complexes, comme celles de ressentir, d’élaborer et d’inventer. C’est souvent cette deuxième forme d’intelligence que le grand public associe au concept d’« intelligence artificielle ». Il est clair que ces avancées n’entrent pas dans le cadre de ces capacités actuelles. Ces limitations relèvent à la fois d’aspects mathématiques fondamentaux, mais également d’éléments technologiques liés à la capacité de traiter rapidement un très gros volume d’informations.
2. Du neurone biologique aux réseaux de neurones formels
Une partie des techniques de l’Intelligence Artificielle repose sur l’utilisation de neurones artificiels, également appelé neurones formels, dont le fonctionnement très simplifié est inspiré de celui des neurones biologiques. La constitution d’un neurone biologique est très complexe. On montre sur la figure 1a une vue fonctionnelle simplifiée. Sensible à des sollicitations de diverses natures, un neurone capte ces signaux incidents par l’intermédiaire de filaments appelés dendrites. Ceux sont les portes d’entrée « neuronales » de l’information. Chaque dendrite est connectée à une synapse par qui l’information incidente est amenée, en provenance d’un autre neurone ou d’une cellule. Le noyau est chargé de déterminer le signal d’activation produit en fonction de l’état des signaux incidents. Le signal d’activation produit (unique pour chaque neurone) est alors transmis par l’axone à d’autres cellules ou neurones. L’axone est le prolongement du neurone et permet son interconnexion avec d’autres neurones ou cellules grâce à une liaison synaptique. La figure 1b montre une vue d’artiste de deux neurones biologiques connectés par une synapse.
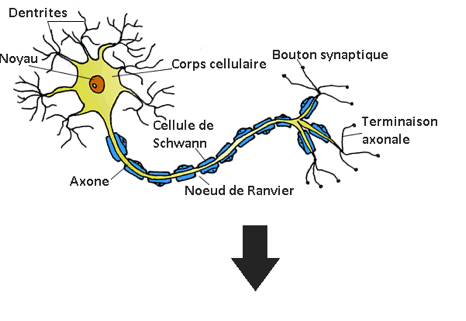
Figure 1a – Représentation d’un neurone biologique
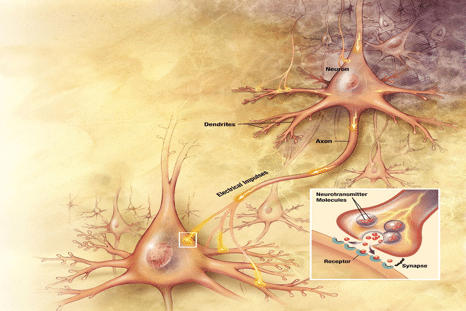
Figure 1b – Illustration de deux neurones connectés par une synapse
Le premier neurone formel est proposé en 1943 par McCulloch et Pitts, dont le schéma présenté sur la figure 2 est une évolution. Chaque neurone est composé de N entrées connectées à l’information extérieure (équivalent aux boutons synaptiques des dendrites) et reliées à une fonction chargée de « combiner » les signaux incidents. Il s’agit en général d’une somme pondérée, dont le résultat contrôle l’intensité du signal d’activation produit à la sortie du neurone.
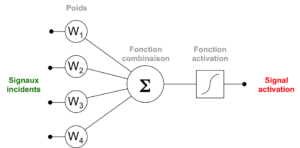
Figure 2 – Schéma d’un neurone formel
3. Les réseaux de neurones pour l’extraction et le stockage de l’information
La puissance de calcul et d’interprétation du cerveau d’un être vivant est le résultat de l’interconnexion d’un grand nombre de ces neurones, de l’ordre de plusieurs milliards, appelé réseau de neurones. Dans les années 1950, Franck Rosenblatt propose un premier concept de réseau appelé « perceptron » [1], qui s’avère être le plus simple des réseaux. Minsky et Papert, fondateurs du laboratoire d’intelligence artificiel du MIT, montrent dans leur ouvrage Perceptron paru en 1969 [2], les lacunes de ce premier modèle. Ce qui a entraîné la mise en sommeil des études sur les réseaux de neurones durant les années 1970.
Il faut attendre 1982 et les travaux de Hopfield [3] pour donner une impulsion nouvelle à cette discipline, en jetant les ponts entre la physique statistique et les réseaux de neurones. Ce résultat constitue le prélude de 20 années de recherche qui déboucheront sur l’avènement industriel des techniques liées à l’apprentissage profond [4], [5], à travers la découverte de procédures d’apprentissage efficaces et industrialisables.
La figure 3 illustre ces avancées à travers trois réseaux agencés de manières différentes. Les neurones sont représentés par les cercles blancs et les liaisons synaptiques par les traits pleins. L’apport de l’apprentissage non-supervisé sur la compréhension de ces structures a été mis en évidence.
La figure 3a, illustrant le cas où les neurones sont tous interconnectés, représente un réseau de Hopfield. Aucune hiérarchie n’apparaît dans ce système car aucune distinction n’est faite entre les neurones (exemple d’application : mémoire adressable par son contenu). Le réseau illustré sur la figure 3b est également un réseau entièrement connecté dans lequel a été introduite une partition des neurones en deux groupes : visibles et invisibles. Les neurones visibles sont connectés directement au signal incident, alors que la couche de neurones cachés est chargée « d’enregistrer » une forme synthétique au fur et à mesure de l’observation d’exemples. Ces réseaux portent le nom de machine de Boltzmann et ont été découvert en 1985 par Hinton et Sejnonwski [5], et ouvrent la voie de l’apprentissage neuronal non-supervisé, c’est-à-dire sans exemple préalablement annoté.
L’on ne perçoit pas encore la structure en couches du réseau, qui sera introduite par Hinton en 2002 avec les machines de Boltzmann restreintes (RBM, Restricted Boltzmann Machine), illustré sur la figure 3c. Cette structure est très intéressante car elle permet une procédure d’apprentissage non-supervisé efficace [6], fournissant une hiérarchie des caractéristiques intrinsèques d’un jeu de données complexes, comme un ensemble d’images. Dans ce schéma, les liaisons synaptiques entre neurones de même nature sont supprimées, donnant lieu à une structure en couches des neurones visibles et cachés.
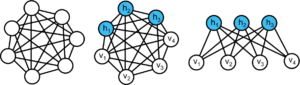
a) Hopfield (1982) b) Machine de Boltzmann (1986) c) Machine de Boltzmann restreinte (2002)
Figure 3. Évolution des réseaux de neurones : un chemin vers l’apprentissage non-supervisé
C’est notamment grâce aux propriétés fondamentales de cette structure proposée en 2002 par Hinton, et des réseaux structurés spécifiquement pour l’analyse d’images (CNN, Convolutional Neural Network) [7], que l’on observe aujourd’hui de nombreuses applications industrielles du deep learning.

