




Deep Fake
“Il est facile de fabriquer un mauvais deepfake,
mais très difficile d’en faire un qui soit vraiment réussi”Ctrl Shift Face
Vous avez sans doute déjà vu ce fameux extrait stupéfiant de Shining, dans lequel on voit Jim Carrey imiter à la perfection le personnage joué par Jack Nicholson. Nombreux sont ceux qui sont tombés dans le piège de ce deep fake ! https://www.youtube.com/watch?v=AeRofGJ17Sk

Mais qu’est-ce que le Deep Fake exactement ?
Le Deepfake, ou en français, “hyper-trucage”, est une technique d’intelligence artificielle qui consiste à générer de la donnée synthétique très réaliste. Il peut s’appliquer à différents types de données, par exemple une image, une vidéo, un son (musique, voix), ou encore une écriture.
On peut ainsi générer une image réaliste à partir d’un dessin, coloriser des images, transférer un style, restaurer une image, ou encore donner à un visage des expressions, changer le genre de la personne, et même échanger les visages. Dans la vidéo ci-dessus, le visage de Jack Nicholson est remplacé par celui de Jim Carrey dans plusieurs scènes avec des résultats étonnants… et inquiétants.
Ou encore Canteloup sur TF1 avec “la grande métamorphose”, où le visage de l’animateur est remplacé par la personnalité politique qu’il imite.
Avec cette technologie, n’importe qui peut entrer dans la peau d’un président (https://www.youtube.com/watch?v=cQ54GDm1eL0), ou même ressusciter les morts, comme ce fut le cas dans le film Fast and Furious (2015), quelques mois après la disparition de l’acteur Paul Walker dans un accident de voiture.
Comment peut-on arriver à ce genre de résultat ?
Le deep fake existe depuis 2017 (par exemple l’application Face Swap de Snapchat). Alors quoi de nouveau ? Désormais, il n’est plus nécessaire d’être un grand spécialiste des effets spéciaux, une IA s’occupe de tout, grâce au mécanisme des réseaux de neurones profonds appelés « Generative Adversarial Network (GAN) ».
Un premier algorithme, appelé “le générateur” va essayer de générer des imitations aussi crédibles que possible tandis qu’un deuxième algorithme, “le discriminateur” tentera de son côté de détecter les faux le plus rapidement possible. Le générateur est mis à jour à partir du discriminateur. Les deux modèles sont donc entraînés simultanément, le générateur visant à tromper de mieux en mieux le discriminateur, et le second visant à discerner de mieux en mieux le vrai du faux. Les imitations seront donc générées encore et encore, perfectionnées, jusqu’à ce que le second algorithme ne puisse plus les déceler. Le résultat final trompe l’algorithme comme l’oeil humain. Pour plus d’informations, consultez l’article Aquila sur les GAN :
https://www.aquiladata.fr/gan-vers-une-meilleure-estimation-des-distributions/
La translation “image-à-image”, dont le but est de translater les images d’un domaine source vers un domaine cible, est une problématique très investiguée par les GAN. Les quelques systèmes génératifs cités ci-dessous sont des exemples de l’évolution de ces GAN.

Et il en existe bien d’autres encore…
Cependant, dans les GANs traditionnels, l’image générée par le générateur est aléatoire. Par exemple, si l’entraînement a été fait sur le dataset MS-COCO, il peut générer des images de n’importe quel objet qui était présent dans ce dataset.
Afin de remédier à ce défaut, il est possible d’introduire une condition, qui permettra l’apprentissage d’un mapping image-à-image “sous” cette condition. On appelle ces réseaux les “conditional GAN (cGAN)”. Ainsi, avec ces cGAN, il est possible de générer les images que l’on souhaite. Si on veut générer une personne, ils vont générer une personne, en conditionnant le GAN.
Cette condition peut se présenter sous la forme d’une image du domaine cible, donnée en input. L’entraînement du modèle se fait sur une paire d’image “source/cible” et l’application du modèle se fait en lui donnant l’image “source”.
Ainsi, pour une même image source, le résultat de la translation sera contrôlé par l’image “conditionnelle” (ou “cible”) donnée en input de l’entraînement, et les images ainsi générées devraient hériter des caractéristiques spécifiques de l’image conditionnelle.

Dans cet exemple, on peut générer des images de façades réalistes à partir de masques labellisés par des couleurs. La condition étant l’image réelle de la façade correspondante. Pour la colorisation des images noir et blanc, l’image conditionnelle donnée en entrée serait l’image identique en couleur. Pour le passage de jour vers nuit, les images de jour sont appariées aux images conditionnelles représentant le même paysage, mais de nuit.
Aujourd’hui, nous vous présentons un des modèles qui répond à cette problématique, le modèle Pix2pix [1], qui a démontré une très large applicabilité dans différents domaines, et une certaine facilité d’adaptation (reconstruction d’une photo à partir de labels, reconstruction d’objet à partir de contours, colorisation des images etc).
Le modèle Pix2pix
Le modèle Pix2pix [1] est un type de GAN conditionnel (cGAN), dans lequel la génération de l’image en sortie est conditionnée par une image “source” en entrée. Le discriminateur est alimenté par une paire d’image “source” et “cible” et doit déterminer si l’image générée en sortie est une transformation plausible de l’image source. Le discriminateur est “conditionné” par l’image source. Dans l’exemple ci-dessous, on souhaite générer des images de visages à partir de traits caractéristiques, appelés “face landmarks”. Ces derniers représentent la “source”, soit l’image donnée en entrée. Le visage réel représente “la cible”.

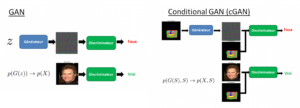
Contrairement aux GANs traditionnels, le discriminateur et le générateur observent la même image donnée en entrée. On parle alors de “joint distribution learning”.
Les GANs sont des modèles génératifs qui apprennent un “mapping” à partir d’un vecteur de bruit aléatoire z vers une image de sortie y, G:{z} → y. A l’inverse, les cGANs apprennent un mapping à partir d’une image x, observée en entrée (ici les face landmarks), et d’un vecteur de bruit aléatoire z, vers une image de sortie y, G:{x,z} → y. Sans le vecteur aléatoire z, les images artificielles générées auraient été déterministes. Le générateur est entraîné à produire des images qui ne peuvent être distinguées des images “réelles” par le discriminateur D, qui lui est entraîné à détecter de mieux en mieux les “fakes” produits par le générateur.
Architecture du réseau
Le Générateur
La structure du générateur est appelée « encodeur-décodeur » et dans pix2pix, deux choix sont possibles :
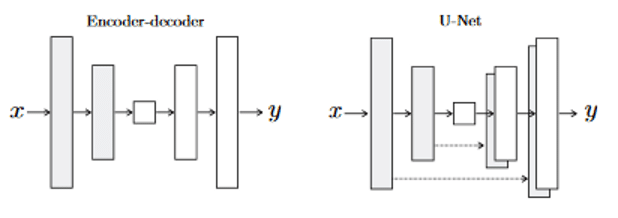
Dans ce genre de réseau, la structure en entrée est grossièrement alignée sur la structure en sortie. L’image en entrée et en sortie sont donc de même taille (256x256x3). L’entrée est comprimée progressivement avec des encodeurs (couches de convolution + fonction d’activation) jusqu’à un goulot d’étranglement, puis le processus est inversé avec des décodeurs (couches de déconvolution + fonction d’activation). Cependant, il est préférable que les informations importantes entre l’entrée et la sortie soit directement propagées à travers le net pour éviter la perte d’information spatiale durant la compression. Par exemple, pour la génération de visage, l’entrée et la sortie partagent la localisation de différentes parties du visage.
Les auteurs ont donc utilisé un « U-Net » au lieu d’un encodeur-décodeur. L’architecture est la même, mais avec des « skip connections » connectant directement les couches encodeur aux couches décodeur de manière symétrique. Ces “skip connections” assurent la réutilisabilité des éléments importants et stabilisent l’entraînement et la convergence. Ainsi, les détails importants peuvent être retrouvés lors de la prédiction.
Le Discriminateur (PatchGAN)
Le Discriminateur a pour tâche de prendre deux images, une image d’entrée et une image inconnue (qui sera soit une image cible soit une image de sortie du générateur), et de décider si la deuxième image a été produite par le générateur ou non.
La structure ressemble beaucoup à la section encodeur du générateur, mais fonctionne un peu différemment. La sortie est une image 30×30 où chaque valeur de pixel (0 à 1) représente la crédibilité de la section correspondante de l’image inconnue. Dans l’implémentation Pix2pix, chaque pixel de cette image 30 x 30 correspond à la crédibilité d’un patch 70 x 70 de l’image d’entrée (les patchs se chevauchent beaucoup puisque les images d’entrée font 256 x 256 pixels). L’architecture est appelée « PatchGAN ».
Formation du réseau
Pour former ce réseau, il y a deux étapes : la formation du discriminateur et la formation du générateur.
Pour former le discriminateur, le générateur génère d’abord une image de sortie. Le discriminateur examine la paire entrée/cible et la paire entrée/sortie et décide du réalisme de la paire entrée/sortie. Les poids du discriminateur sont ensuite ajustés en fonction de l’erreur de classification de la paire entrée/sortie et de la paire entrée/cible.
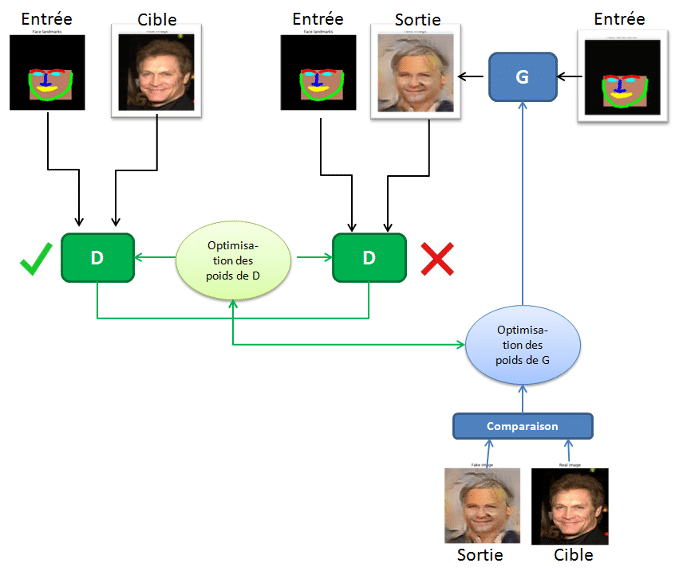
Les poids du générateur sont ensuite ajustés en fonction de la sortie du discriminateur ainsi que de la différence entre la sortie et l’image cible. Lorsque vous formez le générateur sur la sortie du discriminateur, vous calculez en fait les gradients à travers le discriminateur, ce qui signifie que pendant que le discriminateur s’améliore, vous formez le générateur pour battre le discriminateur.
Plus le discriminateur s’améliore, plus le générateur s’améliore, et plus les sorties générées pourraient tromper l’oeil humain.
Ainsi, avec la même image en entrée, par exemple des “face landmarks”, on peut générer des images dans des thématiques différentes, en fonction des images conditionnelles appariées. Par exemple, en gardant les images des face landmarks, on aurait pu générer des portraits, ou même entrer dans la peau d’un personnage. Vous l’aurez compris, il est possible d’appliquer le modèle Pix2pix à une multitude de thématiques variées, par la constitution d’une banque d’images appariées source/cible de qualité et très diversifiée dans la thématique voulue.
Les Limites
Le modèle Pix2pix n’est pas très performant sur les détails. Une version améliorée nommée Pix2pixHD [2 ] a été développée depuis, afin de corriger cette lacune.
Le concept d’images appariées nécessite la création d’une grande base de données, ce qui représente un processus très lourd, voir impossible à générer dans certains domaines. Mais heureusement, des méthodes non-supervisées ont vu le jour.
Notre démonstrateur : « Dans la peau de M. le Président »
Nous avons voulu tester le modèle Pix2pix sur la translation des expressions du visage. Pour cela, nous avons généré une base de données d’images appariées, dans laquelle les sources sont les “face landmarks” du Président et les cibles, ses photos correspondantes.
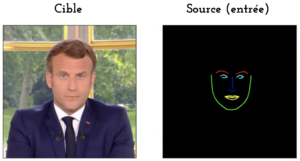
Pour la démonstration, l’entraînement du modèle a été réalisé sur 6000 paires d’images en 10 epochs. Le modèle généré est ensuite appliqué aux face landmarks d’un acteur Aquila, et voici le résultat :
Le modèle a des difficultés lorsque l’on tourne la tête, simplement parce que dans notre base de données, le président ne tourne pratiquement jamais la tête. Cette configuration n’a donc pu être apprise par le modèle, ce qui soulève bien l’importance d’une base de données assez variée.
Exemples d’application en industrie
Les applications de Deep Fake pour les échanges de visage sont nombreuses et très performantes. Certaines, comme DeepNude, sont mêmes basées sur le modèle Pix2pix. Les applications des modèles Pix2pix sont diverses. Dans le secteur immobilier par exemple, les travaux de NVIDIA, nommés ArchiGAN [3], permettent un ameublement automatique des pièces, ou même de choisir le style des plans générés.

L’industrie de la cosmétique est également très friande de ce genre de modèles, qui permettent de proposer des tests virtuels des produits de maquillage par exemple.
Pour aller un peu plus loin dans la théorie
Ces réseaux ne se contentent pas seulement d’apprendre le mapping d’une image donnée en entrée vers une image en sortie, mais apprennent une fonction de coût pour entraîner ce mapping. Les GANs apprennent une fonction de coût qui s’adapte aux données, c’est pourquoi ils peuvent être appliqués à une multitude de tâches.
La fonction de coût :
La fonction de coût d’un GAN traditionnel s’exprime ainsi :
(1) ![\begin{equation*} L_cGAN (G,D)=E_y [log D(y)] +E_(x,z) [log(1 - D(G(x,z))] \end{equation*}](https://www.aquiladata.fr/wp-content/ql-cache/quicklatex.com-7827f93f77d73755c69f62d0fec850ac_l3.png "Rendered by QuickLaTeX.com")
Et la fonction de coût d’un cGAN s’exprime ainsi :
(2) ![\begin{equation*} L_cGAN (G,D) = E_(x,y) [log D(x,y) + E_(x,z) [log(1 - D(x,G(x,z))] \end{equation*}](https://www.aquiladata.fr/wp-content/ql-cache/quicklatex.com-85c189c2b9ae55f8a8f8b249ff17ac45_l3.png "Rendered by QuickLaTeX.com")
où G est le générateur qui tente de minimiser cette fonction objective, D le discriminateur qui tente de la maximiser, x l’image observée en entrée, y l’image générée en sortie, z le vecteur aléatoire. On peut écrire :
(3) 
Le discriminateur ici observe x.
Des études précédentes ont montré l’avantage de combiner la fonction objective du GAN avec une fonction de coût plus traditionnelle, comme la régularisation L1 ou L2, pour minimiser le coût entre l’image générée et l’originale. Les auteurs ont choisi d’introduire la régularisation L1, étant donné qu’elle permet de réduire le flou. Le travail du discriminateur reste le même, tandis que le générateur sera updaté par le coût L1 mesuré entre l’image générée et l’image originale x. Cette fonction de coût additionnelle va aider le générateur à générer des translations plausibles de l’image source.
Cette fonction s’écrit ainsi :
(4) ![\begin{equation*} L_L1 (G) = E_(x,y,z) [||y - G(x,z)||_1] \end{equation*}](https://www.aquiladata.fr/wp-content/ql-cache/quicklatex.com-a8e17b1dd03053df3714f91d6595ab32_l3.png "Rendered by QuickLaTeX.com")
Le coût L1 est la somme de toutes les différences absolues entre toutes les valeurs de pixels de l’image originale et celles de l’image générée. Ainsi, la fonction de coût final de Pix2pix s’écrit :
(5) 
Il s’agit donc de minimiser cette fonction.


